If you spend enough time building C# applications, you eventually run into this question:
Should my business logic talk directly to Entity Framework DbContext, or should I put a repository layer in between?
That is where the Repository pattern comes in.
The Repository pattern is a common way to separate data access code from the rest of your application. It gives your services and business logic a cleaner interface for working with data, without forcing them to know the details of Entity Framework queries, tracking behavior, or persistence concerns.
At the same time, this is one of those topics where developers often get pushed into extremes. Some teams add a repository for every entity no matter what. Other teams insist repositories are always unnecessary because Entity Framework Core already behaves like a repository and unit of work.
In practice, the answer is more nuanced.
In this article, I’ll explain what the Repository pattern is, why teams use it, how to implement it with Entity Framework Core, and when it actually helps versus when it just adds abstraction for no real benefit.
What is the Repository Pattern?
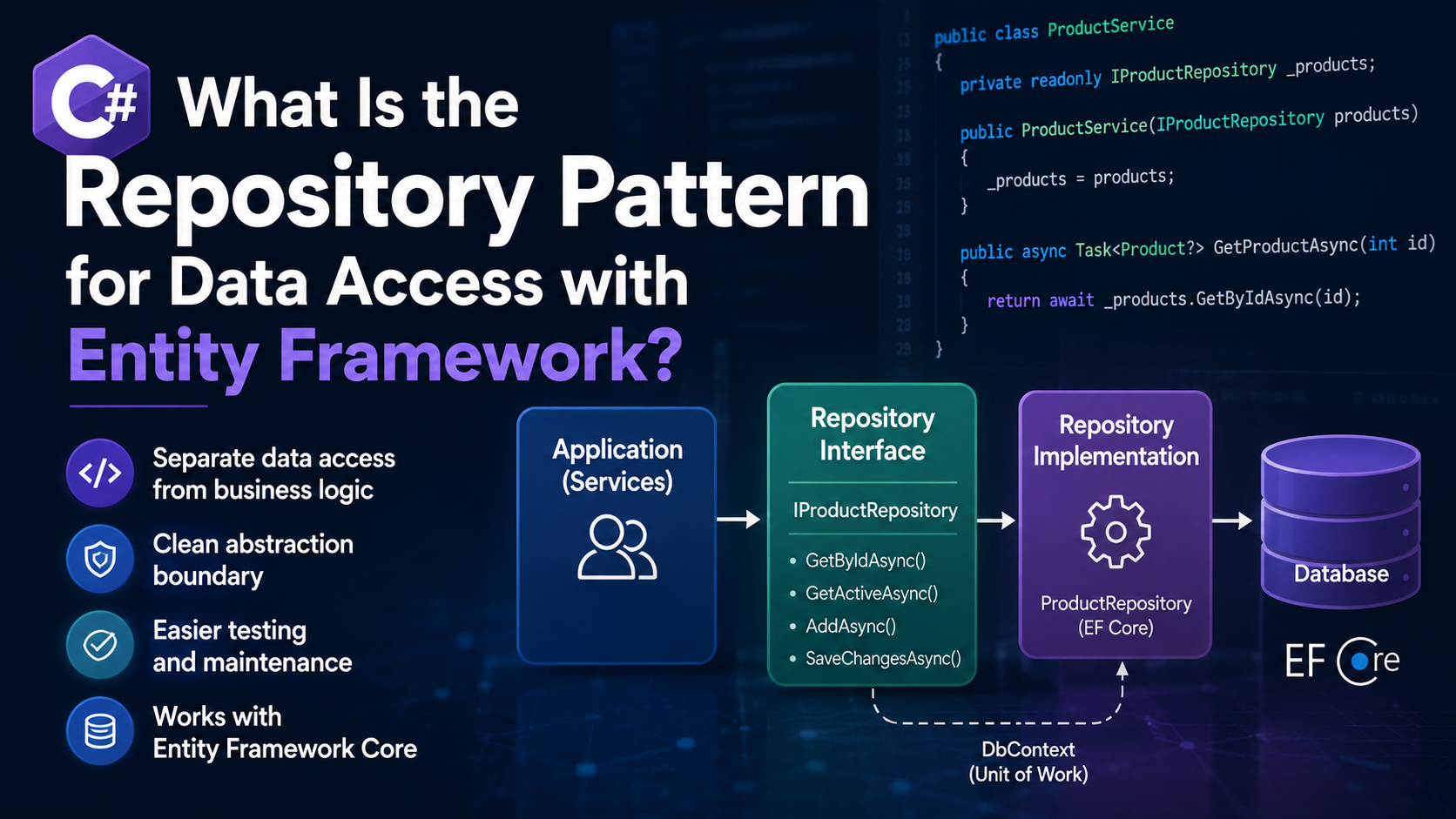
The Repository pattern is a design pattern that places a layer between your application code and the database access technology.
Instead of having your services or controllers call Entity Framework directly, they call a repository that exposes operations in terms the application actually cares about.
For example, instead of this:
var customer = await _dbContext.Customers
.FirstOrDefaultAsync(x => x.Id == id);
You might have this:
var customer = await _customerRepository.GetByIdAsync(id);
That may not look dramatically different at first, but the goal is important: the rest of the application depends on a business-facing contract instead of depending directly on the persistence details.
A repository typically does things like:
- load entities or aggregates
- save new entities
- update existing entities
- encapsulate common query logic
- hide persistence-specific details from higher-level code
Conceptually, the repository acts like an in-memory collection of domain objects, even though it is backed by a database.
Why use a Repository for data access?
There are a few practical reasons teams use the Repository pattern.
1. It keeps business logic cleaner
When query logic is spread throughout controllers, services, and handlers, it becomes harder to maintain. A repository gives you one place to keep data access code organized.
2. It creates a clear abstraction boundary
If your application code depends on ICustomerRepository instead of AppDbContext, you have a cleaner seam between business behavior and persistence.
That can make refactoring easier later, especially if the application grows beyond simple CRUD.
3. It helps with testing
A repository interface can be mocked or replaced with a fake in unit tests.
That said, I would be careful not to oversell this point. Modern integration testing with EF Core is often a better fit than mocking everything. Still, repositories can make isolated testing easier when the business logic should not care about database details.
4. It centralizes repeated queries
If you keep writing the same Include, filtering, sorting, or projection logic in multiple places, a repository can help centralize it.
How does this relate to Entity Framework Core?
This is the part that causes the most debate.
Entity Framework Core already gives you two important patterns:
DbSet<TEntity>behaves a lot like a repositoryDbContextbehaves a lot like a unit of work
That is why many developers say, “EF Core already is a repository, so adding another repository on top is pointless.”
Sometimes they are right.
If your application is straightforward and your service only needs a couple of focused queries, injecting DbContext directly may be perfectly reasonable.
I touched on this idea in my post on structuring a growing ASP.NET Core application. A separate repository layer is not automatically required just because you are using EF Core.
But there are still cases where a repository adds real value:
- you want to protect the application layer from persistence details
- you have complex query logic repeated in multiple places
- you want richer domain-oriented methods than raw
DbSetaccess provides - you want a consistent abstraction for data access across the application
So the better question is not, “Should I always use repositories with EF Core?”
The better question is, “Does a repository make this codebase clearer, easier to test, and easier to evolve?”
A simple Entity Framework Core example
Let’s walk through a practical example.
Assume you have a Product entity and a DbContext.
public class Product
{
public int Id { get; set; }
public string Name { get; set; } = string.Empty;
public decimal Price { get; set; }
public bool IsActive { get; set; }
}
using Microsoft.EntityFrameworkCore;
public class AppDbContext : DbContext
{
public AppDbContext(DbContextOptions<AppDbContext> options)
: base(options)
{
}
public DbSet<Product> Products => Set<Product>();
}
Without a repository, a service might use DbContext directly.
using Microsoft.EntityFrameworkCore;
public class ProductService
{
private readonly AppDbContext _dbContext;
public ProductService(AppDbContext dbContext)
{
_dbContext = dbContext;
}
public async Task<Product?> GetProductAsync(int id)
{
return await _dbContext.Products
.AsNoTracking()
.FirstOrDefaultAsync(x => x.Id == id && x.IsActive);
}
}
That is not wrong.
In fact, for small applications, that may be the simplest and best option.
But if product-related query logic starts showing up across multiple services, then a repository can clean this up.
Defining a repository interface
Here is a simple repository contract for products:
public interface IProductRepository
{
Task<Product?> GetByIdAsync(int id, CancellationToken cancellationToken = default);
Task<IReadOnlyList<Product>> GetActiveAsync(CancellationToken cancellationToken = default);
Task AddAsync(Product product, CancellationToken cancellationToken = default);
Task SaveChangesAsync(CancellationToken cancellationToken = default);
}
A few things are worth noticing here:
- the interface exposes operations the application actually needs
- it does not expose
IQueryabledirectly - it includes asynchronous methods, which fits EF Core well
- it leaves EF-specific query details inside the implementation
That last point matters. If your repository just returns IQueryable, then you are often leaking persistence concerns back into the calling code and losing much of the value of the abstraction.
Implementing the repository with EF Core
Now here is a concrete repository implementation using Entity Framework Core:
using Microsoft.EntityFrameworkCore;
public class ProductRepository : IProductRepository
{
private readonly AppDbContext _dbContext;
public ProductRepository(AppDbContext dbContext)
{
_dbContext = dbContext;
}
public async Task<Product?> GetByIdAsync(int id, CancellationToken cancellationToken = default)
{
return await _dbContext.Products
.AsNoTracking()
.FirstOrDefaultAsync(x => x.Id == id, cancellationToken);
}
public async Task<IReadOnlyList<Product>> GetActiveAsync(CancellationToken cancellationToken = default)
{
return await _dbContext.Products
.AsNoTracking()
.Where(x => x.IsActive)
.OrderBy(x => x.Name)
.ToListAsync(cancellationToken);
}
public async Task AddAsync(Product product, CancellationToken cancellationToken = default)
{
await _dbContext.Products.AddAsync(product, cancellationToken);
}
public Task SaveChangesAsync(CancellationToken cancellationToken = default)
{
return _dbContext.SaveChangesAsync(cancellationToken);
}
}
This keeps the EF Core-specific behavior in one place:
AsNoTracking()for read-only queriesWhereandOrderByquery compositionToListAsync()andFirstOrDefaultAsync()- persistence through
SaveChangesAsync()
Now the service layer can focus on business behavior instead of query details.
Using the repository in a service
Here is what that service might look like after the refactor:
public class ProductService
{
private readonly IProductRepository _products;
public ProductService(IProductRepository products)
{
_products = products;
}
public async Task<Product?> GetProductAsync(int id, CancellationToken cancellationToken = default)
{
return await _products.GetByIdAsync(id, cancellationToken);
}
public async Task<int> CreateProductAsync(string name, decimal price, CancellationToken cancellationToken = default)
{
var product = new Product
{
Name = name,
Price = price,
IsActive = true
};
await _products.AddAsync(product, cancellationToken);
await _products.SaveChangesAsync(cancellationToken);
return product.Id;
}
}
The service no longer needs to know about:
DbSet<Product>- query syntax
- tracking configuration
- how persistence is performed
It only needs to know what operations are available.
Registering the repository in dependency injection
In an ASP.NET Core application, you would typically register the repository as a scoped service:
builder.Services.AddDbContext<AppDbContext>(options =>
options.UseSqlServer(builder.Configuration.GetConnectionString("DefaultConnection")));
builder.Services.AddScoped<IProductRepository, ProductRepository>();
builder.Services.AddScoped<ProductService>();
Because DbContext is scoped, the repository should be scoped too. If a service depends on EF Core DbContext directly or indirectly, that is usually a strong sign it belongs in the request scope as well.
A common mistake: creating a generic repository for everything
One of the most common ways the Repository pattern gets overused is with a generic repository like this:
public interface IRepository<T>
where T : class
{
Task<T?> GetByIdAsync(int id);
Task AddAsync(T entity);
Task DeleteAsync(T entity);
Task SaveChangesAsync();
}
This looks clean at first, but it often becomes too generic to be useful.
Why?
Because real applications rarely need only generic CRUD operations. They usually need queries that are specific to the domain:
- get active products sorted by name
- get recent orders for a customer
- get invoices due in the next seven days
- get users with a specific permission
Once those kinds of requirements show up, the generic repository either becomes bloated or the calling code starts bypassing it.
That is why I generally prefer feature-specific or aggregate-specific repositories when I use repositories at all.
When a repository makes sense with EF Core
A repository is often a good fit when:
- your application has meaningful business logic beyond simple CRUD
- the same query behavior is repeated in multiple places
- you want the application layer to depend on business-oriented contracts
- you want to add decorators or wrappers around data access behavior
- you want a cleaner seam between persistence and business logic
For example, if you later wanted to add caching or logging around a repository, a repository interface gives you a clean place to do that. That pattern works well with decorators, which I covered in another article about cross-cutting concerns in C# and .NET.
When a repository may be unnecessary
A repository may be unnecessary when:
- your application is small and straightforward
- your services are already simple and clear with direct
DbContextusage - the repository would just duplicate
DbSet<TEntity>methods without adding meaning - you end up writing thin wrappers that add ceremony but not clarity
This is an important point: abstraction is only useful when it simplifies the system.
If it gives you more files, more interfaces, and more indirection without solving a real problem, then it is probably not helping.
Best practices for using repositories with Entity Framework
If you decide to use the Repository pattern with EF Core, these are the practices I recommend:
Keep repositories focused
Prefer repositories that represent a meaningful part of the domain, not a giant catch-all data layer.
Do not leak IQueryable unless you have a very deliberate reason
If the caller still has to build EF Core queries itself, then the repository is not really shielding the rest of the application from persistence concerns.
Keep business logic out of the repository
The repository should handle data access. Business rules should live in services, handlers, or your domain model.
Use async methods consistently
Entity Framework Core supports asynchronous data access well. Use ToListAsync, FirstOrDefaultAsync, AnyAsync, and SaveChangesAsync where appropriate.
Let the abstraction earn its place
Do not add repositories just because a template or architecture diagram says you should. Add them when they make the codebase clearer.
Final thoughts
The Repository pattern for data access is really about separation of concerns.
It gives you a way to keep database access details out of higher-level application code and expose a cleaner, more business-oriented contract instead.
When used well with Entity Framework Core, a repository can improve maintainability, organization, and testability.
When used mechanically, it can just duplicate what EF Core already gives you and make the application more complicated than it needs to be.
That is why I do not think this should be treated as an always-or-never rule.
Use a repository when it makes the application easier to understand and evolve. Skip it when direct DbContext usage is already simple, clear, and sufficient.
That is usually the better architectural instinct: choose the abstraction that solves a real problem, not the one that just sounds more formal.